Deep dive into LSM tree
With the increase in demand for Write heavy operations, Tradional databases using B-tree becomes a bottleneck, as updating record in b-Tree will result in multiple random IO and updating multiple pages on the disk. B-tree is very good for read heavy operations. For write heavy, we have LSM tree.
Let’s try to understand what LSM tree is how it works behind the scenes
LSM (Log-Structured Merge) Trees are a type of data structure used to efficiently store and retrieve large amounts of data in a dynamic and changing environment.
The need for such a data structure arose due to the limitations of traditional storage systems, such as B-Trees, in handling high write-intensive workloads.
The basic idea behind LSM trees is to combine the benefits of both log-structured file systems and B-Trees.
LSM trees work by organising data into a series of smaller, more manageable files, called SSTables (Sorted String Tables).
What are SSTables?
SSTables (Sorted String Tables) are the building blocks of LSM (Log-Structured Merge) Trees. They are disk-based data structures that store data in a sorted format, making it possible to efficiently search for and retrieve data.
SSTables are the result of the compaction process in LSM trees, where smaller, unsorted data files are merged together to form larger, more organized SSTables.
The data within an SSTable is stored in a sorted manner, making it possible to quickly search for specific data using binary search algorithms
Understand with an example
An SSTable consists of a sorted, immutable sequence of key-value pairs, where each key is unique and corresponds to a single value.
Suppose we have a database of employee records, where each record has a unique employee ID and contains information such as name, age, salary, and department. We could represent this data as an SSTable with the following structure
+-------------+-----------+-----------+-----------+
| Employee ID | Name | Age | Salary | Department |
+-------------+-----------+-----------+-----------+
| 1001 | John Doe | 30 | $50,000 | HR |
+-------------+-----------+-----------+-----------+
| 1002 | Jane Doe | 25 | $40,000 | IT |
+-------------+-----------+-----------+-----------+
| 1003 | Bob Smith | 35 | $60,000 | Sales |
+-------------+-----------+-----------+-----------+In this example, the SSTable contains three key-value pairs, one for each employee record.
The keys are the employee IDs, and the values are the remaining fields in the record. The keys are sorted in ascending order to allow for efficient binary search and range queries.
When a read operation is performed, the SSTable is consulted to retrieve the value associated with a given key (employee ID). For example, if we wanted to retrieve the record for employee ID 1002, the SSTable would be searched using the index to locate the corresponding block. The value associated with the key 1002 would then be returned.
I hope this gives you an understanding of how SSTable works.
An SSTable typically contains the following information:
- Key-value pairs: The primary data stored in the SSTable. Each key-value pair represents a single record in the database.
- Bloom filter: A data structure used to quickly determine whether a key is present in the SSTable or not.
- Index: A data structure used to map keys to the corresponding block in the SSTable. This allows for efficient lookups by key.
- Compression: SSTables are typically compressed using algorithms such as Snappy or LZ4 to reduce disk space usage.
Bloom Filter
A bloom filter is a data structure that is used to determine whether an element is a member of a set or not. In the context of an SSTable, the Bloom filter is used to determine whether a given key is present in the SSTable or not.
The Bloom filter provides a quick and efficient way to check for the presence of a key, without having to perform a full disk scan.
Understand with an Example
Suppose, we have an SSTable with a large number of keys and we want to check if a key k is present in the SSTable. Rather than scanning the entire SSTable, the Bloom filter can be consulted to quickly determine if the key is likely to be present or not.
If the key is not likely to be present (i.e., the Bloom filter returns false), then the search can be stopped, saving time and disk I/O. If the key is likely to be present (i.e., the Bloom filter returns true), then the SSTable can be searched to retrieve the value associated with the key.
LSM trees are considered dynamic data storage systems because they can handle large amounts of data that are continually changing over time
How LSM tree Works?
LSM trees work by organizing data into a series of smaller, more manageable files, called SSTables (Sorted String Tables), that can be easily merged together to form a larger index. This approach enables fast and efficient storage of data, as well as rapid access to the data.
- First, data is added to the in-memory Memtable.

- When the memtable reaches a certain size, it is flused to disk and become a new SSTable.

- SSTable is then added to the lowest level of the LSM tree.

- As more data is written to the database, multiple SSTables are created and added to the lowest level of LSM tree.

- When the lowest level of LSM tree becomes too large, the SSTables within it are merged together to form a larger SSTables and are moved to next level of LSM tree.
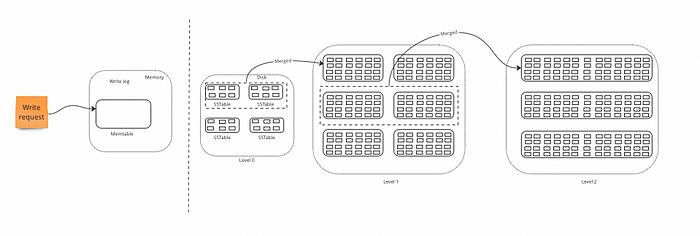
The merging of SSTables are called compaction.
Compaction
Compaction is an essential aspect of LSM Trees and plays a crucial role in the performance and efficiency of the data storage system.
Compaction is the process of merging multiple smaller SSTables into larger ones, which reduces the number of SSTables and the amount of disk space used by the data.
This, in turn, reduces the read amplification, which is the number of disk I/O operations required to retrieve a single record from the SSTables.
Compaction helps to keep the number of SSTables manageable, which is especially important for write-heavy workloads where the number of SSTables can grow quickly
Compaction also helps to maintain the efficiency and performance of the LSM Tree over time. As new data is written to the system, the number of SSTables can grow, which can slow down read operations and increase disk I/O.
Data loss on power off?
If you have noticed, First data is written to the memTable which is on memory, as we know memory is volatile and data on memory is lost if power goes off or something goes wrong. So in this case our data will be lost?
The answer is no!
In an LSM tree, the memtable is used as a temporary storage structure for new data that is being written to the database. When power goes off, any data that has not yet been flushed to disk and compacted into an SSTable will be lost.
To prevent data loss in the event of power failure, LSM trees often implement a write-ahead logging mechanism, where data changes are first written to a log on disk before being committed to the memtable.
This way, in the event of power loss, the data in the log can be used to recover any data that was lost from the memtable.
Advantages of LSM Trees There are several key advantages of using LSM trees, including:
- High write-throughput: LSM trees are designed to handle high write-intensive workloads, making them a good choice for environments where there is a large amount of incoming write traffic.
- Rapid data access: LSM trees are optimized for fast data access, making it possible to quickly retrieve data from large datasets.
- Efficient storage: By breaking down data into smaller SSTables and merging them together as they grow larger, LSM trees are able to efficiently store large amounts of data on disk.
- Dynamic and changing environment: LSM trees are designed to handle dynamic and changing data, making them a good choice for environments where data is constantly being added, updated, and deleted.
Disadvantages of LSM Trees While LSM trees offer many advantages, there are also some disadvantages to consider, including:
- Increased disk usage: The compaction process used by LSM trees can result in increased disk usage, as multiple copies of the same data may be stored on disk.
- Complexity: LSM trees can be complex to implement and maintain, and may require a high level of expertise to properly set up and manage.
- Increased memory usage: LSM trees can be memory-intensive, and may require a significant amount of memory to store the data in memory.
I hope this blog, gives you an understanding of what the LSM tree is how is it useful and can be used.
If you like this blog and interested in reading more content like this do check out my other blogs & follow for email updates.
Do checkout these blogs:
- Deep dive into System design
- Most commonly used algorithms.
- Consistent Hashing
- Bit , Bytes And Memory Management
- CAP Theorem Simplified
- Event Driven Architecture
Other Architecture blogs:
Other Life changing blogs for productivity and Focus:
