Consistent Hashing
In this blog, we’ll talk about what is consistent hashing and why we need to use it and how it can be used. Let’s first understand why we need to use consistent hashing.
Why Consistent Hashing?
In our previous blog about system design. We define a problem where one server is not able to server our heavy load of traffic and we need something reliable, so we thought of scaling our server horizontally and adding a load balancer on top of it to redirect traffic to each server equally.
When a client sends a request to a load balancer, the load balancer routes the request to one of the servers in its pool of servers using a load balancing algorithm.
There are several different load balancing algorithms that can be used to determine which server to send the request to. Some common algorithms include:
- Round-robin: The load balancer sends requests to servers in a rotation, sending the next request to the next server in the list.
- Least connections: The load balancer sends requests to the server with the least number of active connections.
- Least response time: The load balancer sends requests to the server that has the lowest response time for previous requests.
- Weighted round-robin: The load balancer sends requests to servers in a rotation, but the rotation is based on the weight assigned to each server. Servers with a higher weight receive a higher proportion of the requests.
The load balancer can also use health checks to monitor the status of each server and route requests only to healthy servers. This helps to ensure that requests are not sent to servers that are down or experiencing issues.
HASH FUNCTION
Load balancers also use a hash function to redirect the user to server which they were connected before. A hash function is a mathematical function that takes an input value (also called a key) and returns a fixed-size output value (also called a hash or a digest).
Hash function are good, in case where we want to connect a user to same server throughout its course of actions so that we can server them better based on the session state or cache we have stored for that user on that same server.

If another user connects, load balancer will calculate the hash value and decide which server to assign that request. It is important to assign the same user to same server as we have cache and other things related to that user saved on the server that can help us to server they better.
This looks good, but the problem is when servers are added and removed from the server pool.
Let’s understand how it is a problem.

Let’s suppose , due to increase in load, we added a new server and now we have 5 servers to serve the traffic. Now, the issue is when user A will make a request, it will be handled by completely different server because our servers increased and so does our hash function output, because before it was calculating the value considering 4 servers but now we have 5. so This is where the whole issue lies.
Adding or Removing a server will result in shuffling the users on different servers and this can be a big problem for us. So what is the solution?
This is where Consistent Hashing comes in.
WHAT IS CONSISTENT HASHING?
Consistent hashing is a hashing technique that allows nodes to be added or removed from a hash table (also called a distributed hash table or DHT) without significantly altering the mapping of keys to nodes.
It means , we can add and remove servers without doing much of the shuffling of connected users.
In consistent hashing, the set of all possible keys is called the “hash space.” The hash space is typically represented as a circle, with the keys distributed evenly around the circle. This representation is called a “hash ring.”

Once we connect our hash space and repesents it like a ring that will be called hash ring.


Each node in the distributed system is also assigned a position on the hash ring, and is responsible for storing the keys that fall within a certain range of the hash ring. The range of keys that a node is responsible for is called its “zone.”
Using a hash function, we can map servers onto the ring.

Now, we have our server mapped on to the ring, let’s understand how the requests will be handled by these servers.

Each request will be handled by the first server it encounter by moving to the clockwise direction. Based on the hash function, r1 is places on the ring between s4 and s1, so r1 will be handled by the server s1. r2 is places on the ring between s2 and s1, so r2 will be handled by the server s2. r3 is places on the ring between s4 and s3, so r3 will be handled by the server s4.
When a new request is inserted into the system, it is hashed and placed on the hash ring at a specific position.
This looks good. Now what will happen when we add and remove servers.
Adding A New Server
Adding a new server to the ring will require only redistribution of few keys as we discussed before.
Let’s suppose we added a new server and based on the hash function , it is placed on the ring between s3 and s4.

When we add a new server s5, it is mapped on the ring between s3 and s4. So the only requests that needs to be shuffled is r3. So from now on, r3 is handled by the server s5.
Removing A Server
Removing a server from the ring will require only redistribution of few keys as well.
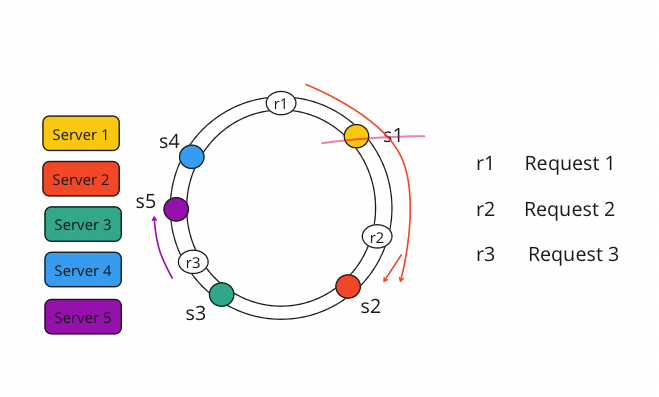
Let’s suppose s1 goes down, then the only request that need to redistributed is r1 . Based on the clockwise approach, r1 will be handled by the server s2.
This looks good as we have solved large redistribution of requests if any server is added or removed. But there are few issues with this approach as well.
Issues With Consistent Hashing
- Uneven hash space.
- Non uniform request distribution
Uneven hash space
It is impossible to keep the size of each hash space on the ring same for all servers considering that new servers can be added and existing one can be removed.
It is possible that the size of the hash space on the ring assigned to each server is very small or fairly large.
Non uniform request distribution
Non uniform request distribution means distribution of most of the requests to one server and little or no request to other servers. It might happen that our hash function will create results that will make most of the requests to be handled by one server only.
So, how do we fix these two issues?
A technique called virtual nodes is used to solve these two issues.
Virtual nodes
Virtual nodes refers to real nodes. Each server we have on the ring has multiple virtual nodes. Let’s try to understand it with an example
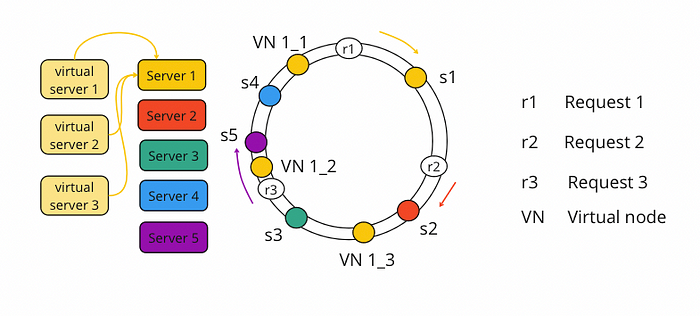
In above diagram, we have 3 virtual nodes for server 1 that points to server 1, it means any request handled by the virtual nodes will be redirected to s1.
A server can have more virtual nodes as well 3 is just an arbitrary number.
Now according to our virtual nodes, request r3 will be handed by VN 1_2 as it was handled by s5.
As the number of virtual nodes increases, the distribution of requests become more balanced. We can use different hash functions for our virtual nodes to distribute them across hash ring.
I hope this gives you an understanding of how consistent hashing works and why we use it.
Overall, consistent hashing is a useful tool for distributing keys evenly across a group of nodes in a distributed system, and for minimizing the impact of changes to the system on the distribution of keys. It can be an effective way to scale and manage distributed systems, and is worth considering for organizations that need to maintain high levels of performance and availability.
Checkout my system design blog:
Checkout these Algorithm blogs:
Other Life changing blogs for productivity and Focus:
