Deep dive Into System Design
In this blog, we’ll discuss important things that we need to consider while designing systems. The main objective of this blog is to make awareness about how we can design systems that are capable of scaling when load surge.
The purpose of system design is to create solutions that meet the needs of users and stakeholders, and that are efficient, scalable, and maintainable. It involves considering a wide range of factors including performance, reliability, security, usability, and cost.
Designing a system that can scale to millions of users is challenging and requires continuous improvements. There are many things that we need to keep in mind while designing systems that server thousands or even millions of users. We’ll discuss few of the things that can help you make better decisions.
Here we Go
Scaling
In traditional softwares we have frontend connecting to a backend server and that backend server is connecting to a database.

This works well for small applications. But as our traffic grows, one server will not able to serve our purpose and one database will not be able to serve all our data related queries, so we need to scale our servers and database.
There are two ways to scale our server:
- Vertical Scaling
- Horizontal Scaling
Vertical Scaling
Vertical scaling, referred to as “scale up”, means the process of adding more power (CPU, RAM, etc.) to your server. When there are not that much of users , scaling up the server is recommended but as the load grows on the server , it become costly to scale servers up and there is a limit to that as well. Also there is a high chance of failover as there is single point of failure, if the server goes down, the website will go down.
It can be an effective way to scale a system, as it allows organisations to quickly and easily add more resources to a single node in the system.
In vertical scaling, due to heavy load , the user can face slow response time and even server connection failure.

Horizontal Scaling
Horizontal scaling is adding more servers. Horizontal scaling leads to solution for problems that we face during vertical scaling. It can reduce failovers as there is no single point of failure, if one server goes down, other one can take its place and server the user.

Horizontal scaling is often used to increase the performance and capacity of a system in order to handle increasing workloads or to support new functionality.
Now the question come in that how can the client know which server to connect to as there are multiple servers, The answer is they don’t have to know it and they don’t have to worry about it. Load balancer solve this problem.
Clients connect to only one domain and that domain is linked to load balancer. It is the job of the load balancer to redirect the client to a server that is free or less utilised.
Load Balancer
A load balancer is responsible for distributing the traffic among multiple web servers. Load balancer is the only point of contact for the client, they don’t have to worry about connecting to the server.
Load balancer connects to the servers using private IP. Private IP is an IP address that is reachable by the servers in the same network, so it adds an extra set of security.

Load balancers can be configured to use various algorithms to determine how to distribute traffic across the different nodes in a system. Some common algorithms include round-robin, least connections, and weighted round-robin. The choice of algorithm depends on the specific needs and characteristics of the system and the workload being handled.
Database
Now that our system is able to handle sufficient load, we need to take care of our database as well, as we can’t just run database in our server and scale them up. As doing so will leads to data inconsistency. For example.
User A connects to Server 1 and User B connects to Server 2. All the work that they do will updated on their respective servers. Now, let’s suppose network fluctuated for User A and it reconnected to another server let’s say Server 2 . Server 2 will not be able to serve the user as all its data was stored on Server 1. To solve this issue, we need to keep database outside.
Keeping the database outside our server will help us to scale our database.
Replication
Database replication is the process of copying data from one database to another, in order to maintain an up-to-date copy of the data on multiple servers.
Database replication is often used to improve the performance and availability of a database system by distributing the workload across multiple servers and providing a backup copy of the data in case of a server failure. It can also be used to ensure data consistency between different locations or to allow users to access the data from multiple locations.
If one database nodes goes down, other one is there to support the request.
There are several different types of database replication, including master-slave replication, peer-to-peer replication, and multi-master replication.
- In master-slave replication, one database server (the master) is responsible for writing data, while one or more other servers (the slaves) receive copies of the data and serve read requests. This is a simple and efficient way to set up database replication, but it does not allow the slaves to write data
- In peer-to-peer replication, all servers can both read and write data and are responsible for replicating data to other servers.This allows for more flexibility and can improve performance for write-heavy workloads, but it can also be more complex to set up and manage.
- In multi-master replication, multiple servers can write data and are responsible for replicating data to each other.
This allows for even more flexibility and can improve performance for write-heavy workloads, but it can also be more complex to set up and manage, and requires careful conflict resolution to ensure data consistency.
In master-slave replications, master database generally only supports write operations. A slave database gets copies of the data from the master database and only supports read operations. All the data-modifying commands like insert, delete, or update must be sent to the master database.

Generally, all the writes are done by the master. What if master goes down?
If master database goes down, other slave can become a master and server the purpose. There is a practice of voting that happens between the slave to become a master.
Database Replication provides lot of benefits:
- Improved performance: By distributing the workload across multiple servers, database replication can improve the performance of the database system, especially for read-heavy workloads.
- Increased availability: With database replication, if one server fails, the data can still be accessed from a replica server, which helps to increase the availability of the database system.
- Data consistency: Database replication can help to ensure that data is consistent across multiple servers, which is important for maintaining accurate and up-to-date information.
- Data backup: Replica servers can serve as a backup of the data in case of a disaster or data loss on the primary server.
Sharding
Sharding plays an important role in large scale architectures. Database sharding is a database design technique that involves splitting a large database into smaller, more manageable pieces called shards. Each shard is stored on a separate server.
Sharding make use of Shard key to distribute data across shards.
The main advantage of database sharding is that it allows a database system to scale horizontally, meaning that it can handle a larger volume of data and requests by adding more servers to the database cluster. This can improve the performance and availability of the database system, especially for high-traffic applications or data sets that are too large to fit on a single server.

Let’s understand sharding with an example:
Imagine that you have a large database that stores customer information for an e-commerce website. The database is growing rapidly and is starting to become slow and difficult to manage. To improve the performance and scalability of the database, you decide to implement database sharding.
With database sharding, you split the large database into smaller pieces called shards. Each shard is stored on a separate server, and the database system distributes the data across the shards based on a sharding key. For example, you might use the customer’s location as the sharding key, so that all the customers from a particular region are stored on the same shard.
Now, when a user accesses the database to retrieve or update customer information, the database system uses the sharding key to determine which shard the data is stored on. It then sends the request to the appropriate shard, which processes the request and returns the data to the user.
WHICH DATABASE TO CHOOSE
Choosing a database relies on many factors such as:
- Performance
- Scalability
- Availability
Relational Database:
Relational databases are well-suited for structured data that is organized into tables with well-defined relationships between the data items. They are good for storing data that needs to be accessed and updated in a transactional manner, and they support powerful querying and indexing capabilities.
Examples of relational databases include MySQL, Oracle, and Microsoft SQL Server, PostgreSQL.
Relational databases represent and store data in tables and rows
Non-Relational Database
Non-relational databases are better suited for unstructured or semi-structured data that does not fit well into a table-based structure. They are good for storing data that is frequently accessed and updated, and they support horizontal scaling and high availability.
Examples of non-relational databases include MongoDB, Cassandra, and Redis.
These databases are grouped into four categories: key-value stores, graph stores, column stores, and document stores.
CACHE
Caching is a technique used to improve the performance of a system by storing frequently accessed data in a temporary storage area, called a cache, so that it can be quickly retrieved without the need to access the original data source.
Accessing data from disk is costly, so in order to improve latency we can use in memory stores to fetch data more quickly. As read from memory are much better than from disk.
Here are some stats of reading from memory and disk:
- Reading from RAM: 10–100 nanoseconds
- Reading from an SSD: 50–100 microseconds
- Reading from a hard drive: 5–10 milliseconds
There are 10 power 9 nanoseconds , 10 power 6 microseconds and 10 power 3 milliseconds in 1 second.
In order to improve response time and accessing data, we introduce a caching layer, For every read request, we check if data exist in cache or not, if yes then we fetch data from the cache and if not, we fetch the data from database , update cache with that data and return data to user.
Here is a simple flow of how it works:
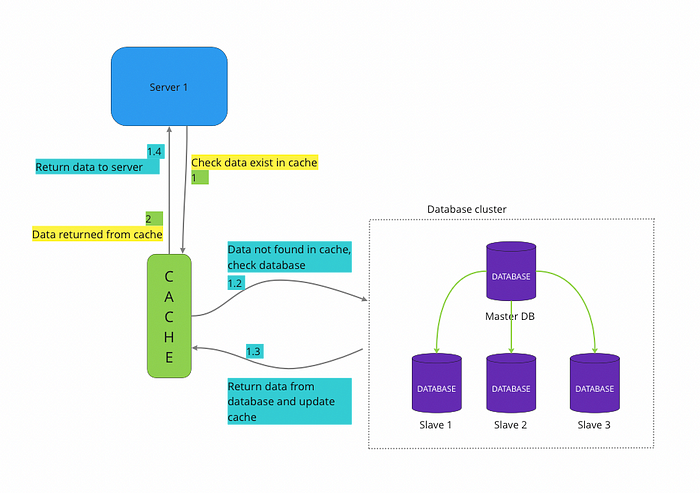
Although, we should not use caching for caching all our data as it will put a hugh load on the memory and will slow down the process. There are few considerations for using a cache:
- Cache size: The size of the cache can impact its effectiveness. A larger cache can store more data and may be more effective at reducing the number of accesses to the underlying data source, but it can also consume more resources and may not be practical if the cache is too large.
- Cache eviction policy: A cache eviction policy determines how the cache handles the replacement of old data with new data when the cache is full. Different policies have different trade-offs in terms of performance and efficiency. For example, a least recently used (LRU) policy will remove the least recently accessed data from the cache, while a first in, first out (FIFO) policy will remove the oldest data.
- Cache expiration: Cache expiration determines how long data is kept in the cache before it is considered stale and is removed. Setting a shorter expiration time can improve the freshness of the data, but it may also increase the number of accesses to the underlying data source.
- Cache consistency: Ensuring cache consistency is important to ensure that the data in the cache is accurate and up-to-date. This may involve invalidating the cache when the underlying data is updated, or using techniques such as cache invalidation or cache stampede protection to ensure that the cache is consistent with the underlying data.
- Cache efficiency: The efficiency of the cache can impact the overall performance of the system. It is important to consider the overhead of maintaining and accessing the cache, and to ensure that the benefits of the cache outweigh the costs.
- Cache usage patterns: Understanding the usage patterns of the cache can help to optimize its configuration and improve its effectiveness. This may involve analyzing the hit rate (the percentage of cache hits vs. misses) and the cache miss rate, and identifying the most frequently accessed data to optimize the cache layout and eviction policy.
Content delivery Network(CDN)
A content delivery network (CDN) is a system of distributed servers that are used to deliver web content to users based on their geographic location. The goal of a CDN is to improve the performance and availability of web content by reducing the distance that the content has to travel and by providing multiple copies of the content that can be accessed from different locations.
CDNs are used to deliver a wide range of web content, including static assets (such as images and videos), dynamic content (such as HTML pages and APIs), and streaming content (such as audio and video streams).
They are commonly used by websites and applications that need to deliver high-bandwidth content to a large number of users around the world.

Here is an example to understand how CDN works:
- Client A sends a request for image.png to a CDN server.
- The CDN server determines the client’s geographic location and selects the server that is closest to the client.
- The selected server retrieves the requested content from the origin server (the server where the content is stored) and sends it back to the client and store the image in the cache.
- If another client B requests the same content again, the CDN server can retrieve it from the cache on the nearest server, which reduces the load on the origin server and improves the performance of the system.
Here are some things to consider when using a CDN:
- Cache expiration: The cache expiration time determines how long the content is stored in the CDN’s cache before it is considered stale and is refreshed from the origin server. Setting a shorter expiration time can improve the freshness of the content, but it may also increase the load on the origin server and the overall cost of the CDN.
- Geographical distribution: A CDN can improve the performance of a website or application by reducing the distance that the content has to travel to reach the user. It is important to consider the geographical distribution of the user base when choosing a CDN and to ensure that the CDN has sufficient coverage in the relevant regions.
- Cost: CDN services can be expensive, especially for high-traffic websites or applications. It is important to carefully consider the cost of the CDN and to ensure that the benefits of the CDN justify the expense.
- Integration: Integrating a CDN into an existing website or application may require some development work, depending on the specific needs and requirements of the system. It is important to carefully plan the integration and to consider the impact on the overall architecture and performance of the system
- Security: CDNs can provide some security benefits, such as protecting against distributed denial of service (DDoS) attacks and offering SSL/TLS encryption for secure content delivery. However, it is important to carefully consider the security implications of using a CDN and to ensure that the CDN meets the security needs of the website or application.
QUEUE
Queue are a best example of event driven architecture and can be used to make the architecture loosely coupled.
Message queue works in a pub/sub model . We have publishers that publish the message to the queue and we have subscribers that consume the messages from the queue & perform actions accordingly.
A message queue is a durable component, stored in memory, that supports asynchronous communication. It serves as a buffer and distributes asynchronous requests.
In a loosely coupled architecture, the components of the system are independent and can operate separately, without tight dependencies on each other.Message queues can help to maintain the loose coupling between the components by allowing them to communicate through a common interface, rather than directly calling each other.
This can improve the flexibility and maintainability of the system, as it allows the components to evolve and be updated independently.
Message queues can also improve the performance of a system by allowing the components to communicate asynchronously, rather than blocking each other while waiting for a response. This can help to reduce the load on the system and allow it to handle a higher volume of requests.
Let’s take an example of how Youtube handles video uploading so fluently.
- When a user uploads a video to YouTube, the website stores the video in a temporary storage location and adds a message to a message queue indicating that a new video has been uploaded.
- The message queue routes the message to a separate component or set of components responsible for processing the video. This could include tasks such as transcoding the video into different formats, generating thumbnail images, and extracting metadata from the video.
- As the processing tasks are completed, the component updates the status of the video and adds additional messages to the queue indicating the next steps that need to be taken. For example, a message might be added to the queue to indicate that the video is ready to be made public, or that it needs to be reviewed by a moderator before it can be published.
- The message queue routes the messages to the appropriate components, which handle the tasks and update the status of the video as necessary.
This approach allows YouTube to handle the video upload and processing process asynchronously, which can improve the performance and scalability of the system. It also allows the different components of the system to be developed and updated independently, which can improve the maintainability of the system.
LOGGING & MONITORING
Logging and monitoring are important in large systems because they provide visibility into the operation and performance of the system, which can help to identify and troubleshoot issues, improve the reliability and availability of the system, and optimize its performance.
Here are some specific benefits of logging and monitoring in large systems:
- Identification and troubleshooting of issues: Logging and monitoring can help to identify problems or issues with the system, such as errors, performance bottlenecks, or security breaches. This can help to quickly identify and fix problems, which can improve the reliability and availability of the system.
- Performance optimization: Monitoring the performance of the system can help to identify areas for optimisation, such as resource utilization, response times, and throughput. This can help to improve the efficiency and effectiveness of the system.
- Capacity planning: Monitoring the usage and performance of the system can help to identify trends and patterns that can inform capacity planning decisions, such as the need to scale up or down, add or remove resources, or upgrade hardware or software.
- Compliance: In some cases, logging and monitoring may be required for compliance purposes, such as for security or regulatory requirements.
- Debugging and development: Logging can also be useful for debugging and development purposes, as it can provide valuable insights into the operation of the system and help to identify and fix problems.
- Alerting: Logging and monitoring systems can be configured to send alerts when certain conditions are met, such as when an error rate exceeds a certain threshold or when a system resource is running low. This can help to identify problems early and take timely action to resolve them.
Conclusion, I have tried to cover all the things that are used in configuring large scale systems. I hope this gives you an idea about how to design systems and how you can design them better. Let me know if i miss something and will try to add that as well.
Checkout these Algorithm blogs:
Other Life changing blogs for productivity and Focus:
